Home > Replicating metatheory results
Replicating metatheory results
In this section we explain how to replicate the metatheory results summarised by Table 2.
-
Download and untar our model files.
$ wget http://johnwickerson.github.com/transactions/artifacts/reproducibility/metatheory.tgz $ tar zxvf metatheory.tgz -
Download, build, and launch the Alloy Analyzer (version 4.2).
$ git clone https://github.com/johnwickerson/alloystar.git $ cd alloystar $ ant $ java -jar dist/alloy4.2.jar -
For each of the 11 model files in the root
metatheory/directory, open the file in the Alloy Analyzer GUI application, set the solver to Plingeling (viaOptions -> Solver -> Plingeling), turn off higher-order solving (viaOptions -> Use higher-order solver: No), and execute the command (viaExecute -> Run). The timings are for a machine with four 16-core Opteron processors and 128GB RAM.Model file Property being checked Event count Expected outcome 1_mono_x86.alsMonotonicity of x86 TM 6 No instance found, ~20m 2_mono_ppc.alsMonotonicity of Power TM 2 Instance found, ~1s 3_mono_arm8.alsMonotonicity of ARMv8 TM 2 Instance found, ~1s 4_mono_c11.alsMonotonicity of C++ TM 6 No instance found, ~91h 5_comp_x86.alsCompilation from C++ TM to x86 TM 6 No instance found, ~14h 6_comp_ppc.alsCompilation from C++ TM to Power TM 6 No instance found, ~16h 7_comp_arm8.alsCompilation from C++ TM to ARMv8 TM 6 No instance found, ~20h 8_hle_x86.alsLock elision for x86 TM 8 Timeout, >48h 9_hle_ppc.alsLock elision for Power TM 9 Timeout, >48h 10_hle_arm8.alsLock elision for ARMv8 TM 7 Instance found, ~63s 11_hle_arm8_fixed.alsLock elision for ARMv8 TM, fixed 8 Timeout, >48h -
For the commands that actually produce a solution, this solution can be viewed using the Alloy Visualizer. To do this, click on
Instance foundto launch the Visualizer. To make the graph as readable as possible, open theProjectionmenu, and tick theExecandPTagboxes.
Examining solutions
Let’s examine a solution from 10_hle_arm8.als. First, as recommended above: open the Projection menu, and tick the Exec and PTag boxes. Note that your solution may not match exactly because events may be relabelled and, moreover, because there are multiple solutions (see Appendix A of the paper).
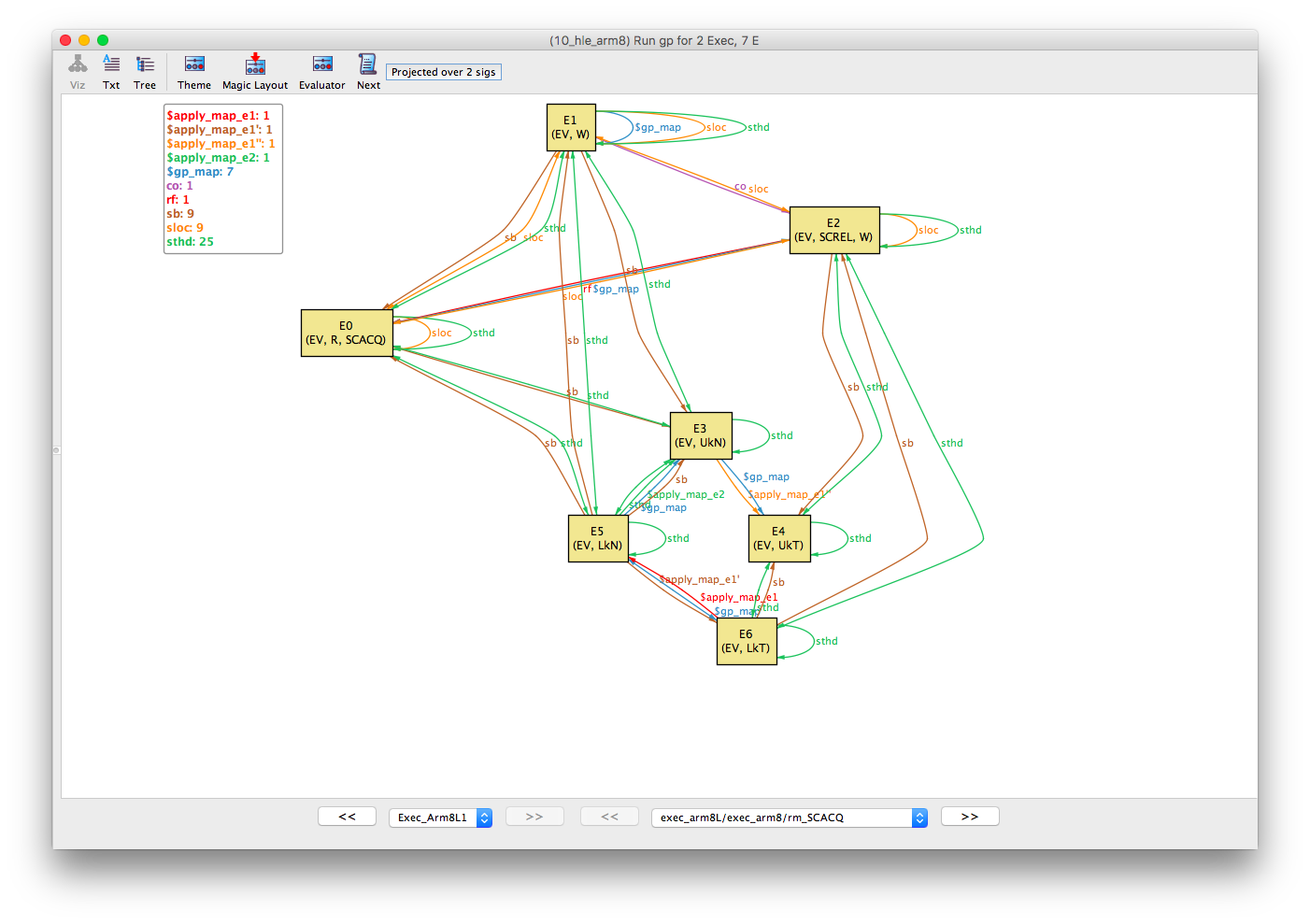
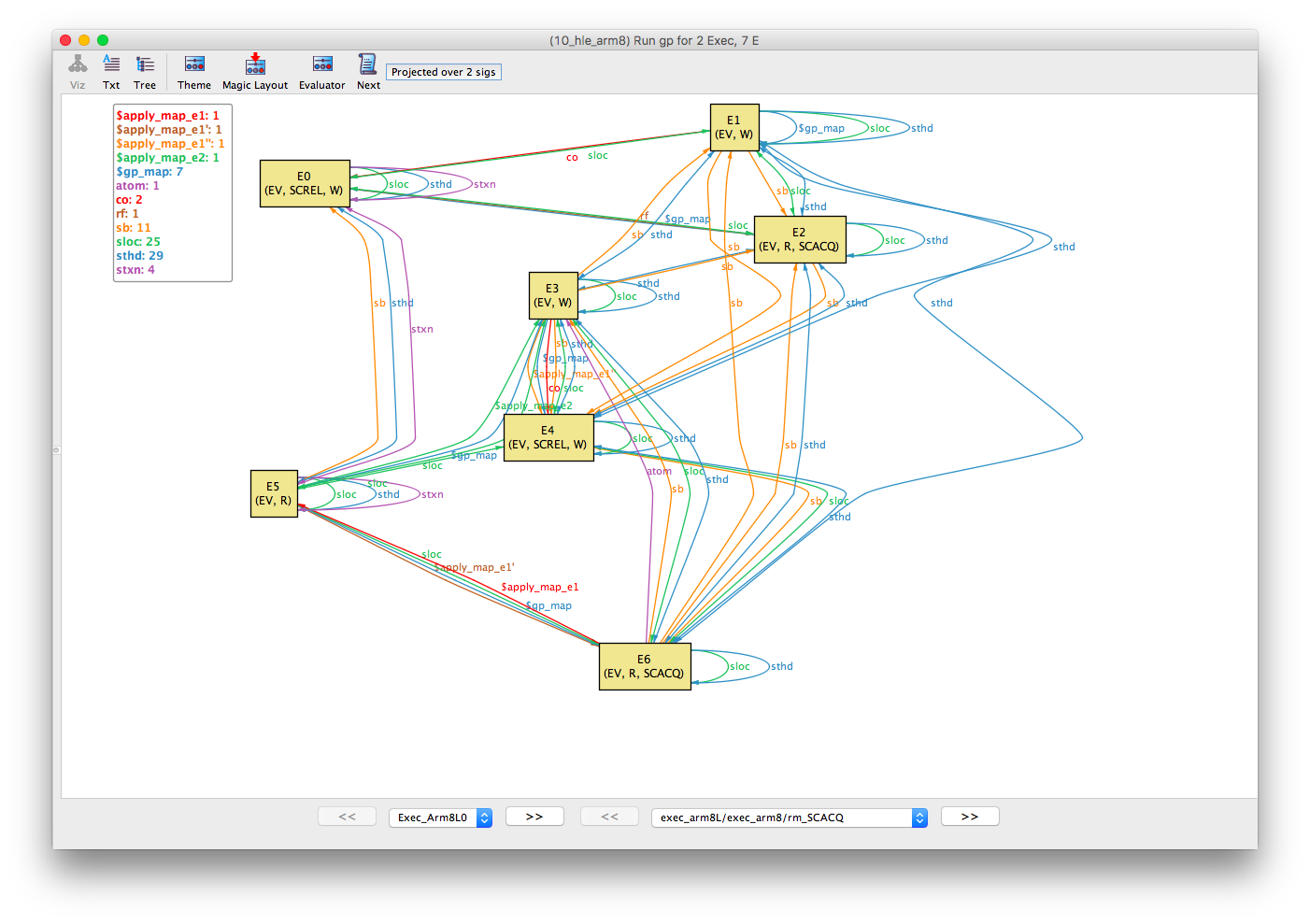
This counterexample is composed of two executions. The abstract execution composed of library calls lock() and unlock() events and a concrete execution where the library calls have been replaced by an ARMv8 spinlock implementation. These are called Exec_Arm8L1 and Exec_Arm8L0, respectively by Alloy. Move between each execution with the << and >> buttons on the bottom-left of the Alloy Visualiser.
This is a counterexample to the soundness of lock elision (as discussed in Section 8.4 of the paper) because the abstract execution is inconsistent and the concrete execution is consistent.
| Abstract execution (inconsistent) | Concrete (consistent) |
|---|---|
 |
 |
The first thing of note is that the syntax of the Alloy solution and the paper differs slightly:
| . | Alloy solution | Paper |
|---|---|---|
| Program order | sb |
po |
| Read-modify-write | atom |
rmw |
| Acquire operation | SCACQ |
Acq |
| Release operation | SCREL |
Rel |
| Lock operation | LkN |
L |
| Unlock operation | UkN |
U |
| Lock operation (tx elided) | LkT |
L^t |
| Unlock operation (tx elided) | UkT |
U^t |
| Mapping relation | gp_map |
\pi |
Abstract
Starting with the abstract library execution (identifiable by the library Lk and Uk events), we can roll over the sthd (same-thread) equivalence relation (in the box in the top-left of the Alloy Visualiser).
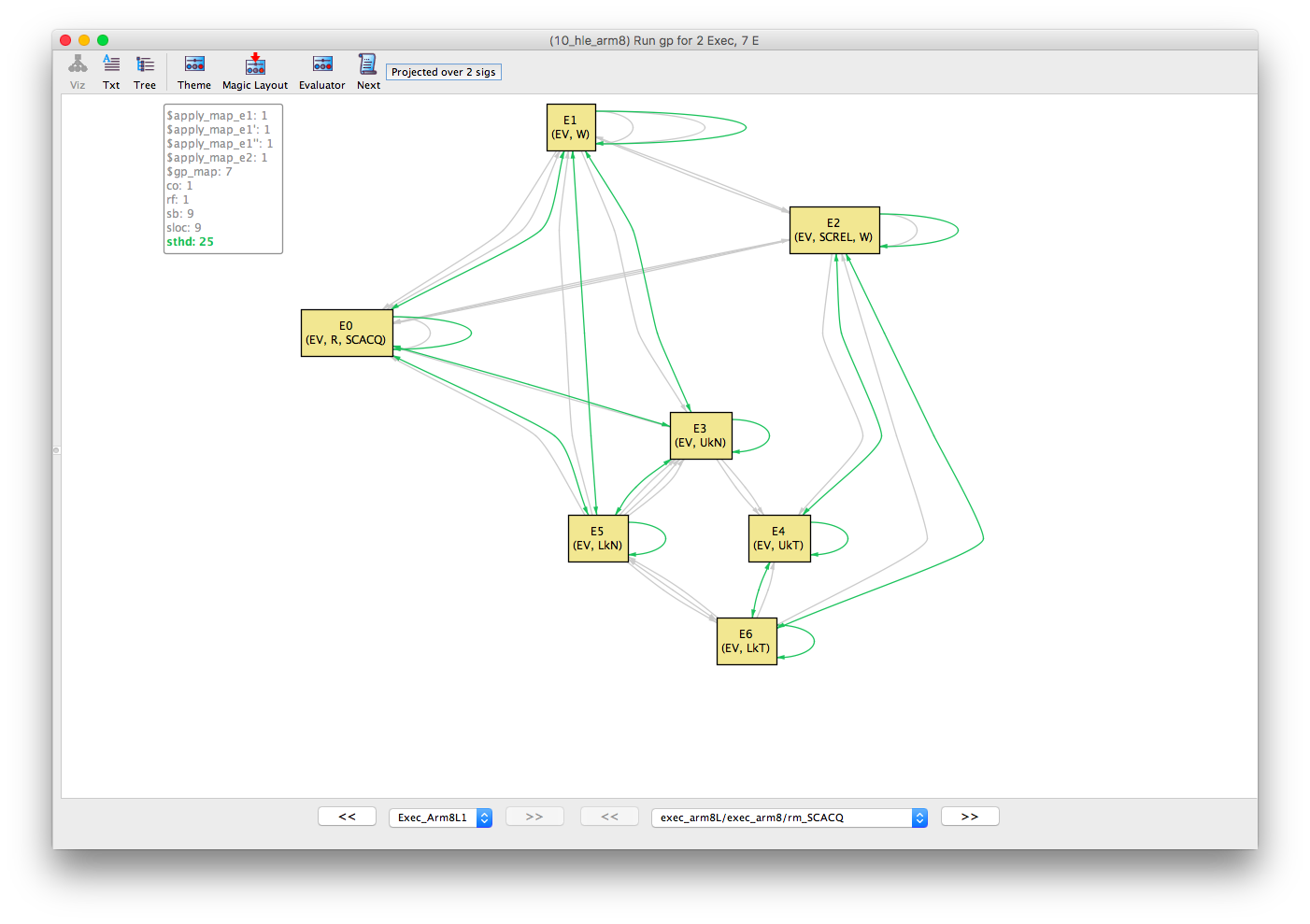
This shows the events partitioned into two threads:
- E0, E1, E3, E5
- E2, E4, E6
Next, roll over the sb (program-order) relation.
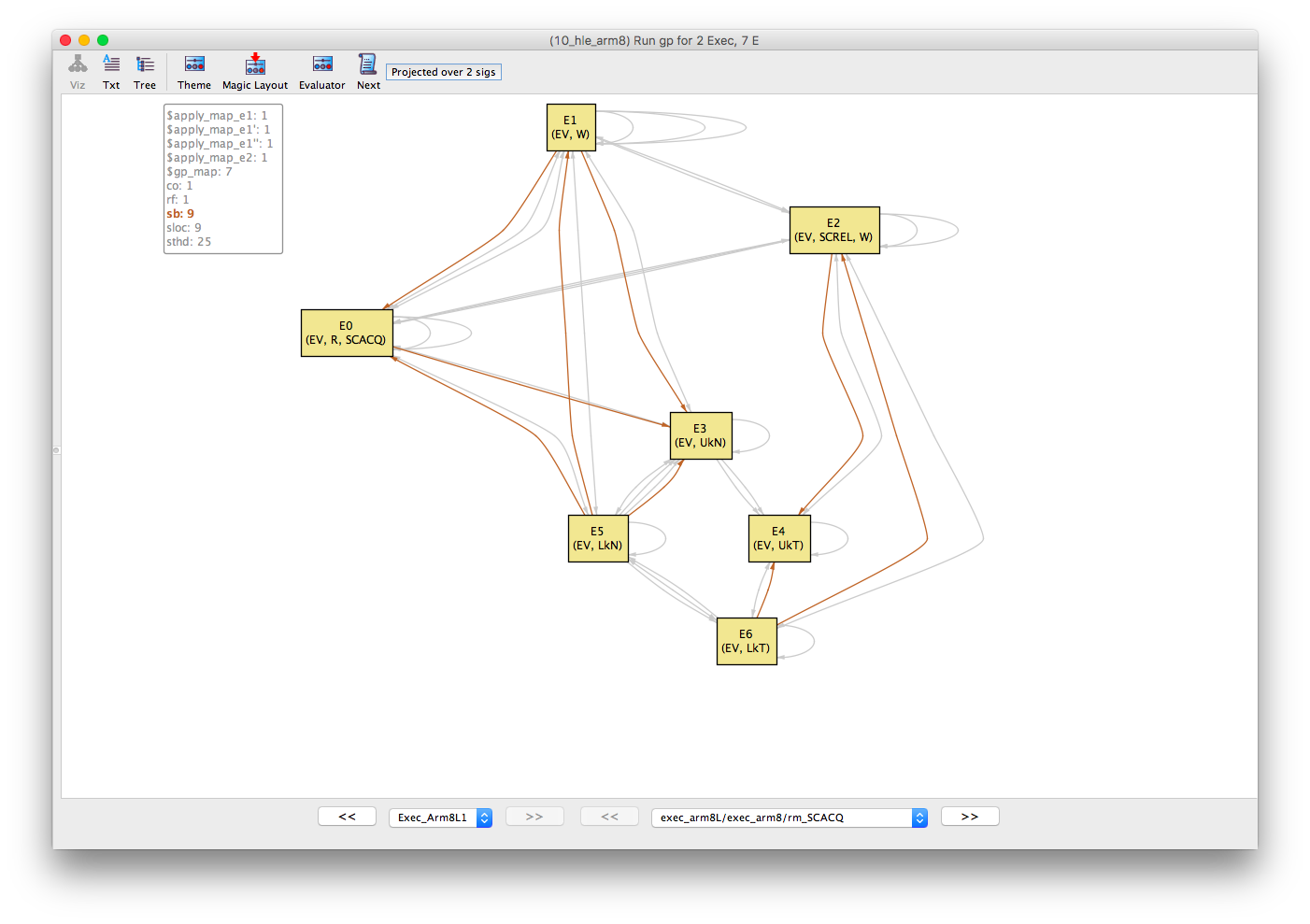
Recall that program-order is transitive. Therefore, we can trace program-order by starting with the event with the highest number of outbound (sb) edges and working down. This shows that the events are ordered in po as follows:
- E5; E1; E0; E3
- E6; E2; E4
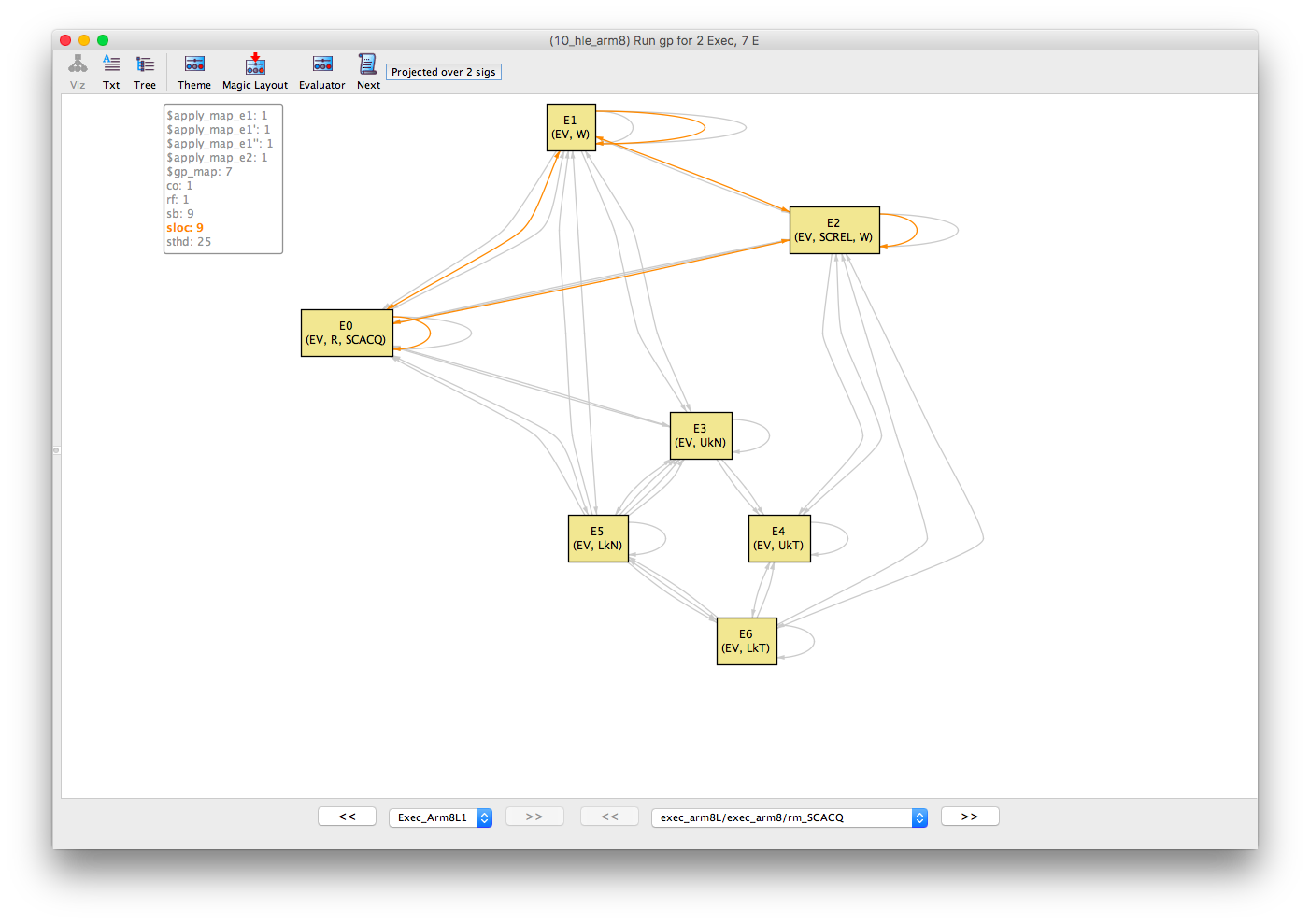
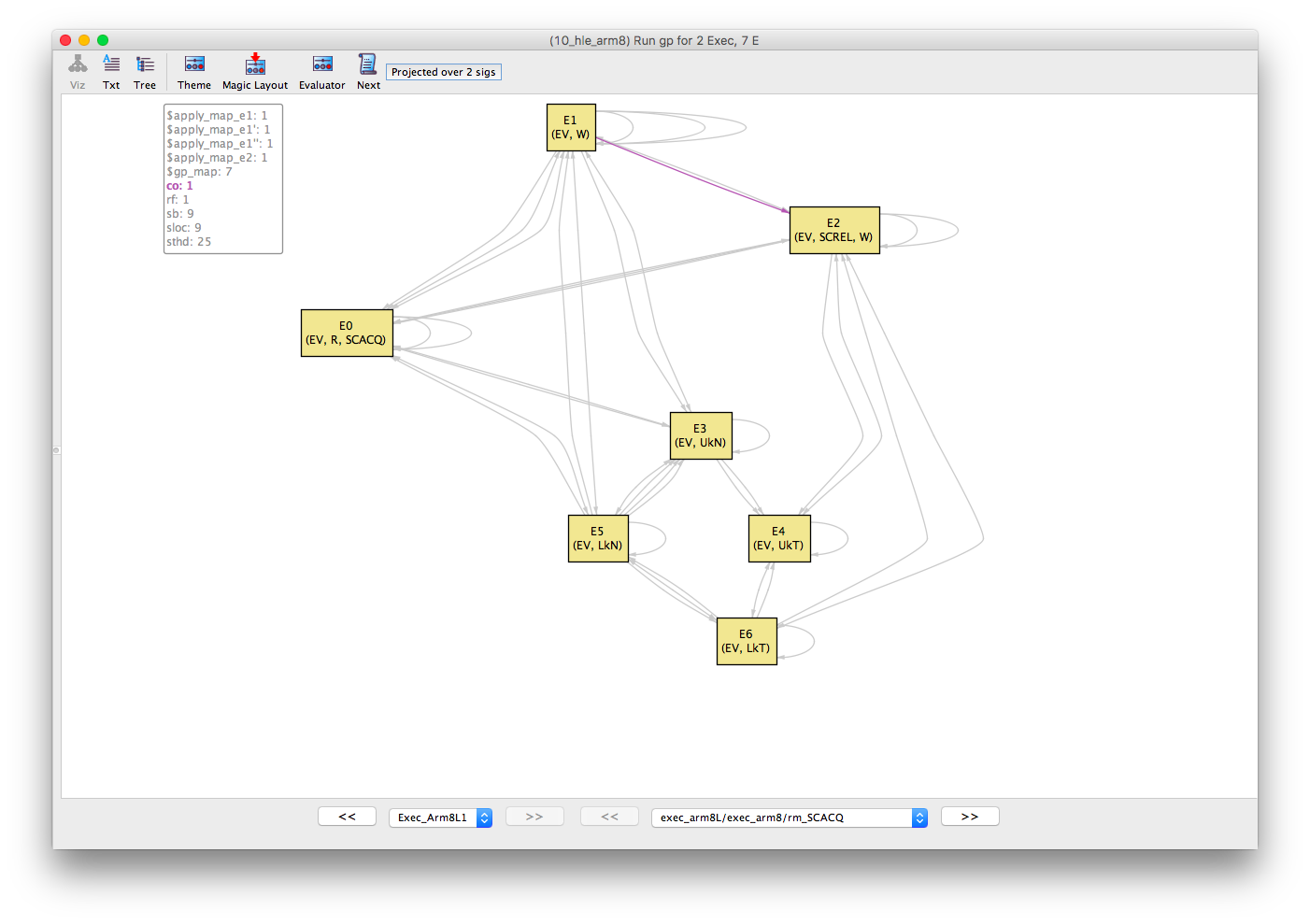
Similarly, the sloc (same-location) equivalence relation shows that E0, E1 and E2 are all events over the same location (let’s call this x). And, finally, the co (coherence) and rf (reads-from) relations show that E1 -co-> E2 -rf-> E0.
sloc |
co |
rf |
|---|---|---|
 |
 |
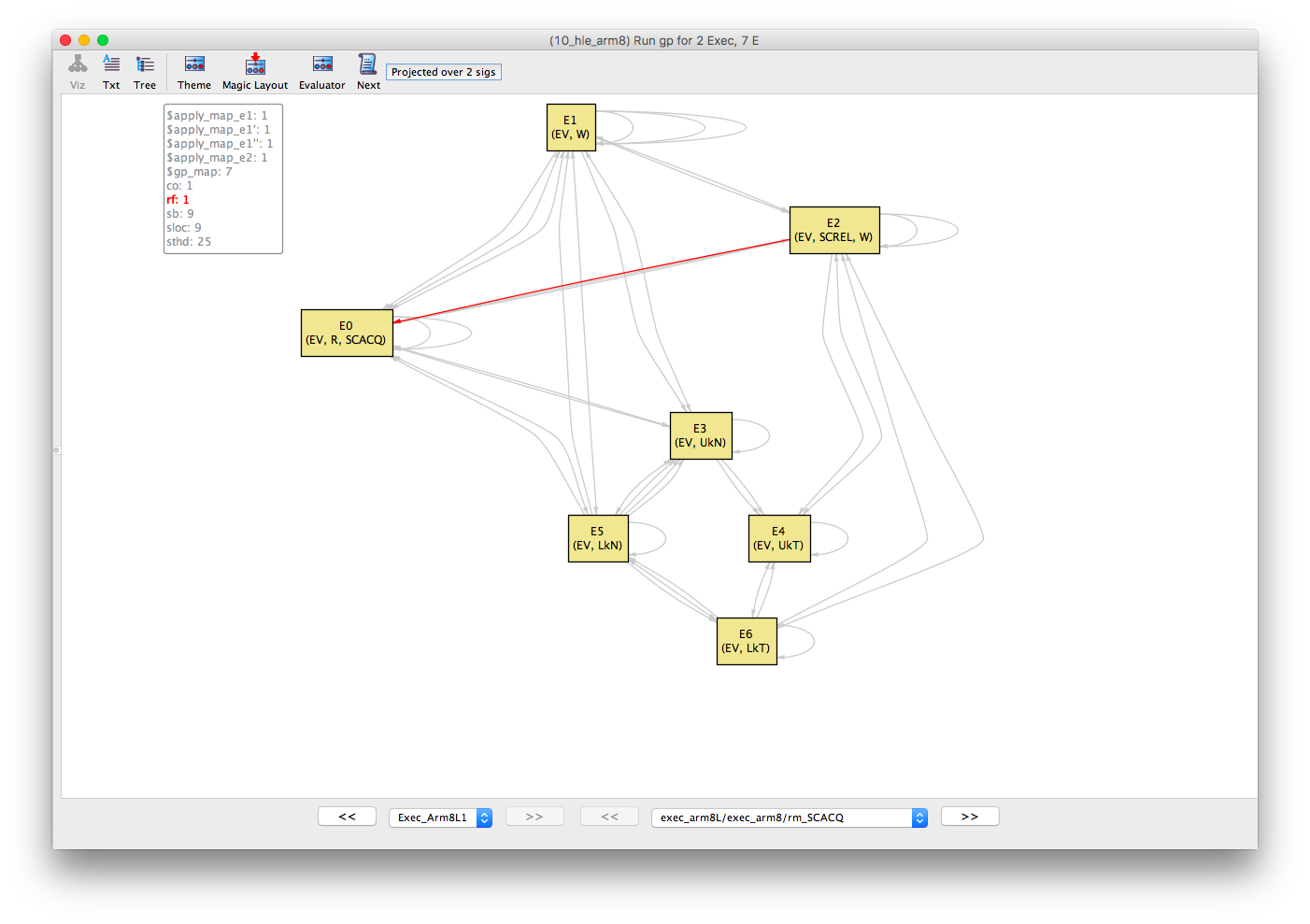 |
If we put this all together then the abstract execution can be drawn as follows. The execution is inconsistent because of the co-rf cycle between the two critical regions. Note that the release and acquire operations on E0 and E2, respectively, are not strictly required to forbid the execution but have been included in this instance.
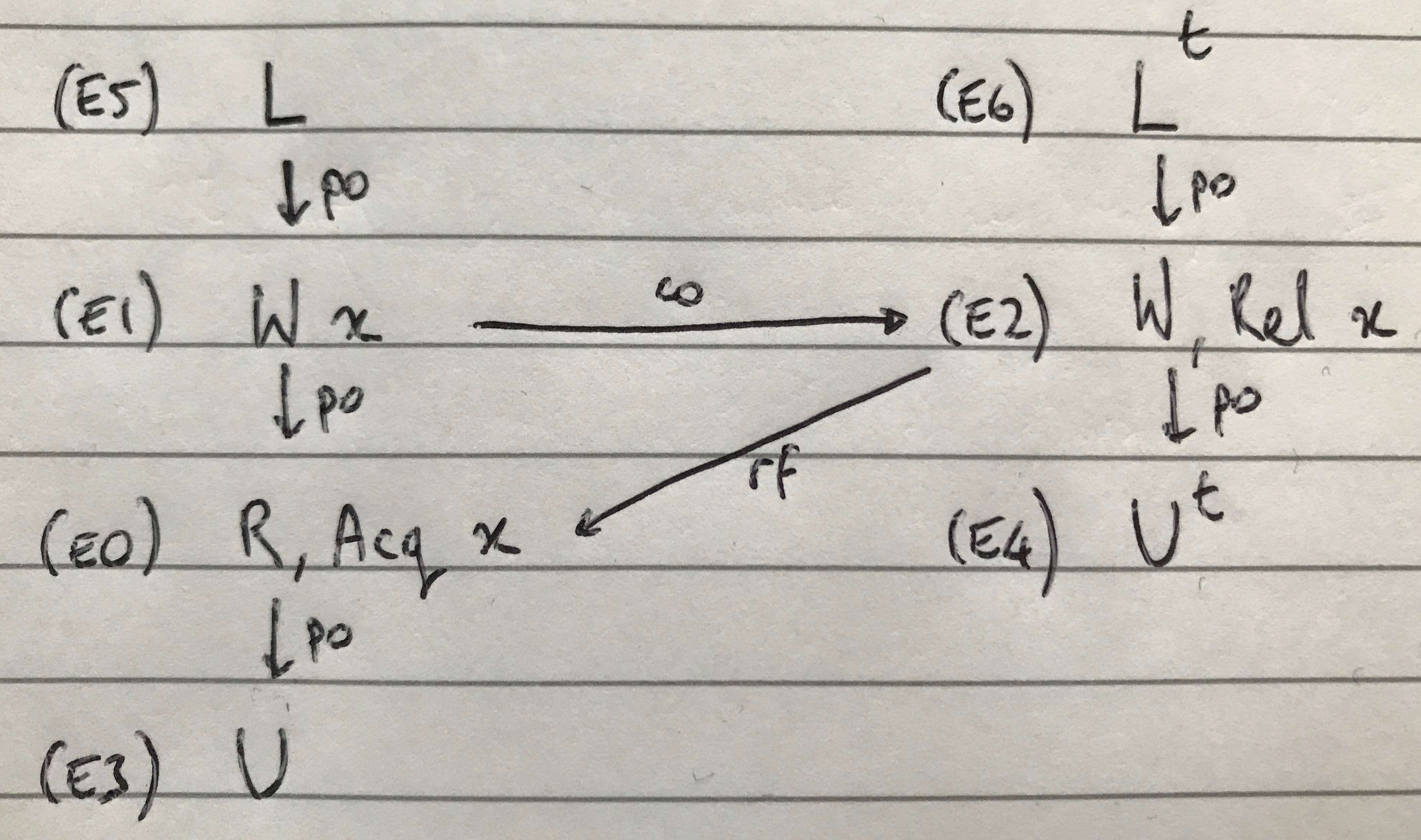
Concrete
Now we turn our attention to the concrete execution.
Following the same method for sthd and sb as above, we can partition the events into two threads. Moreover, the stxn (same successful transaction) equivalence relation shows that E5 and E0 are within the same transaction.
- E6; E3; E1; E2; E4
- E5; E0
sthd |
sb |
stxn |
|---|---|---|
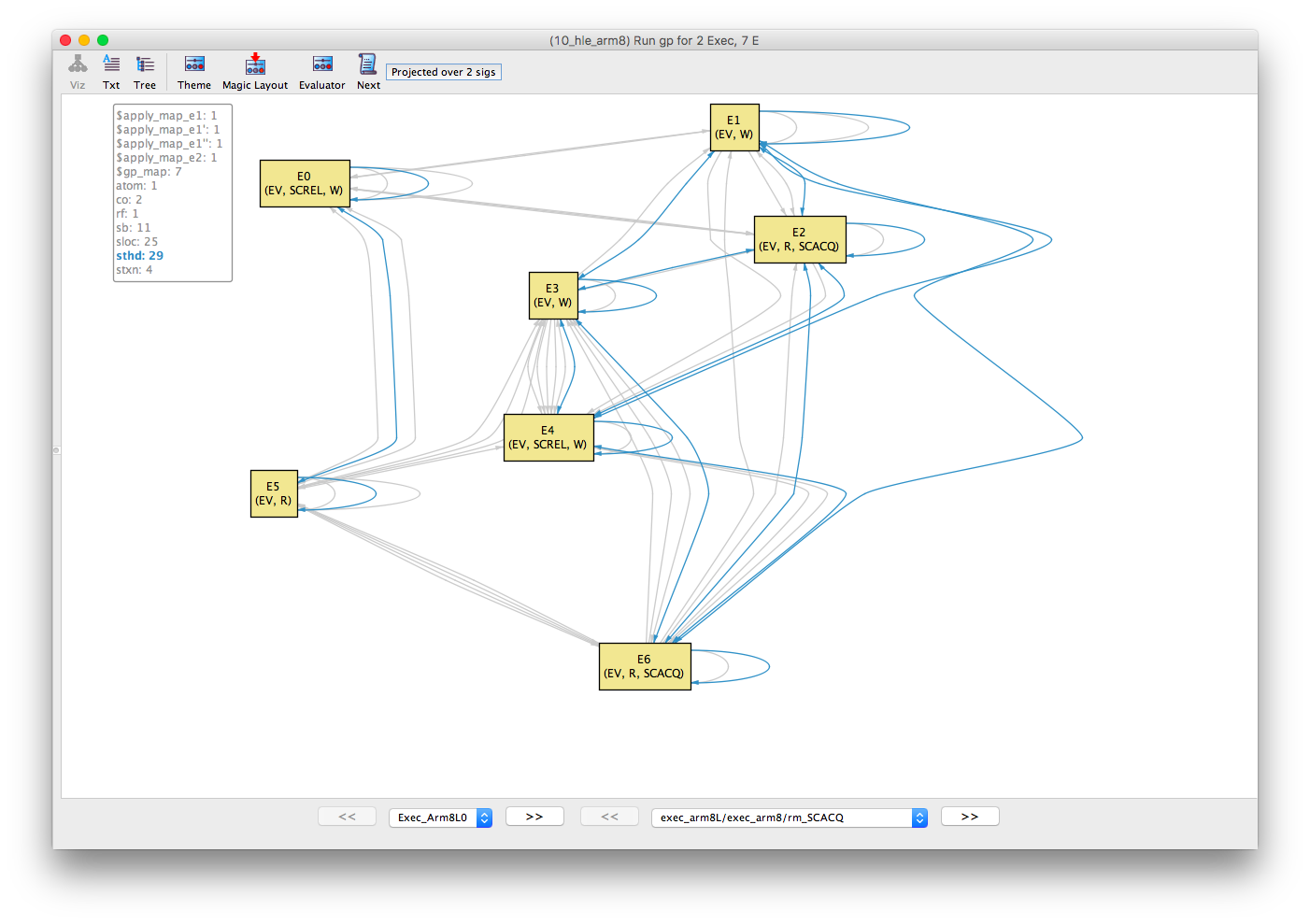 |
|
|
The sloc (same-location) equivalence relation shows that E0, E1 and E2 are all events over the same location (let’s call this x); and E3, E4, E5 and E6 are over another location (let’s call this m).
The co (coherence) and rf (reads-from) relations show that E1 -co-> E0 -rf-> E2; and that E3 -co-> E4. We can deduce the fr (from-reads) relations E5 -fr-> E3 and E6 -fr-> E3 because both E5 and E3 are reads of the same location x without an rf edge (i.e., they implicitly read-from the initial write).
sloc |
co |
rf |
|---|---|---|
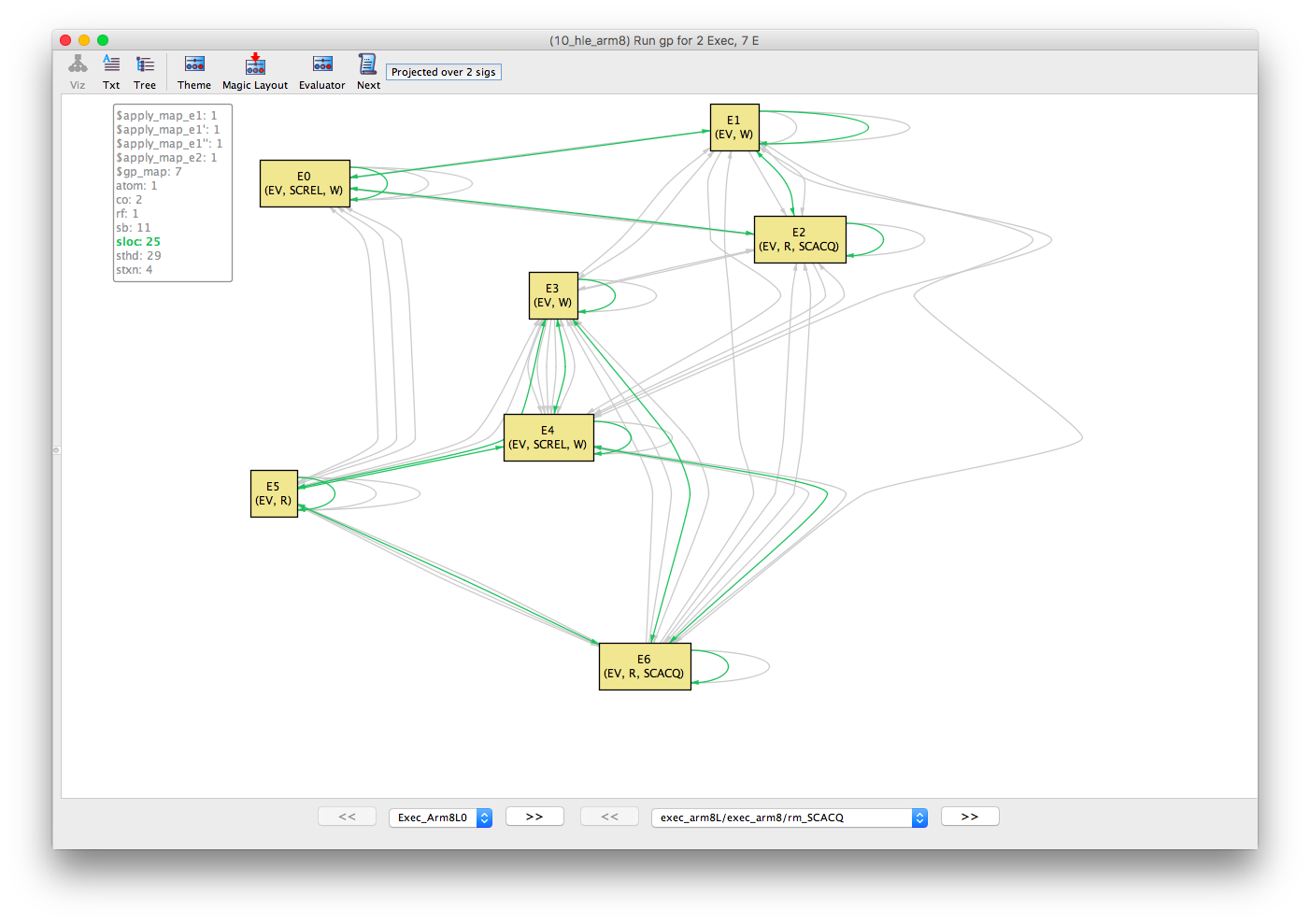 |
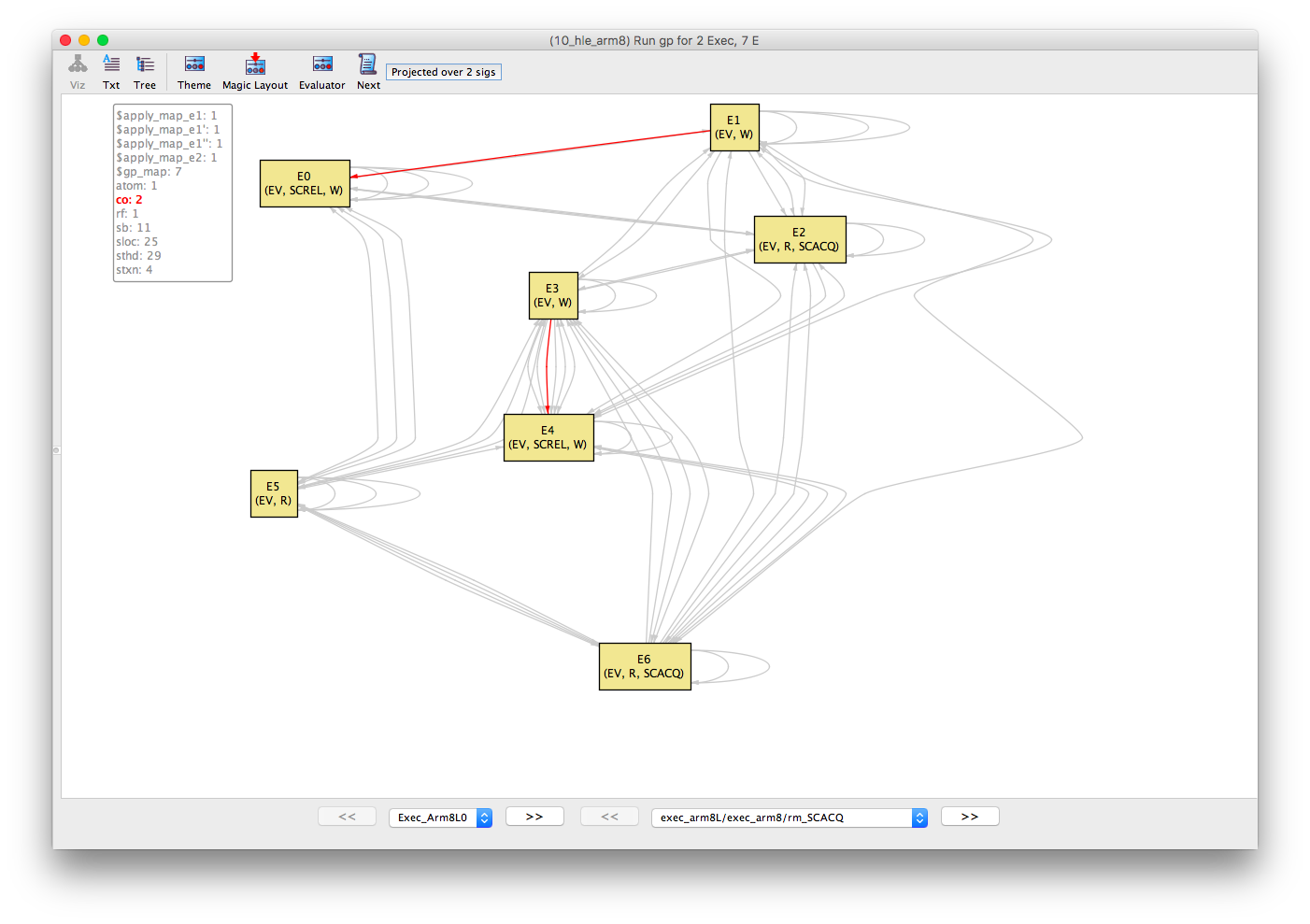 |
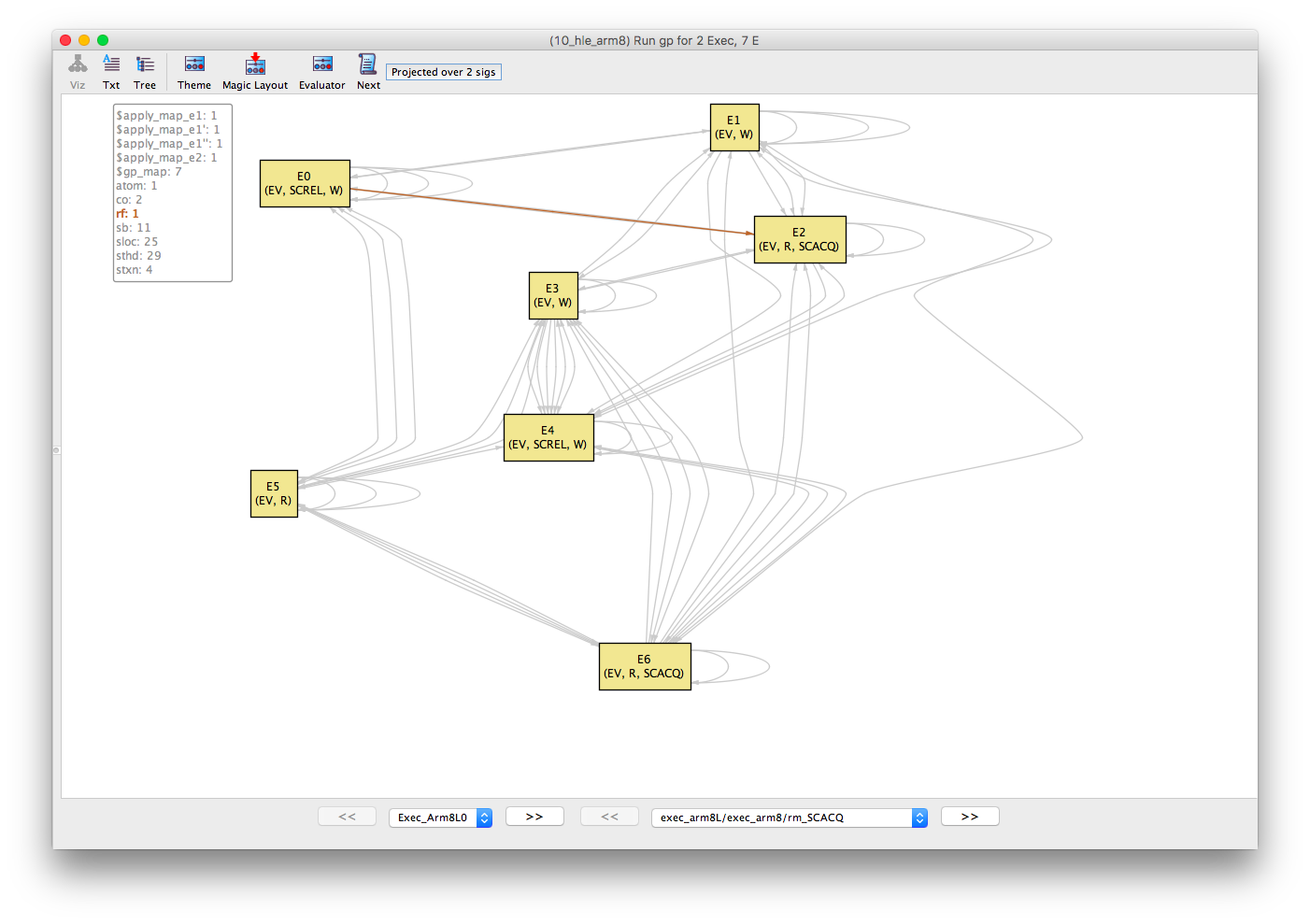 |
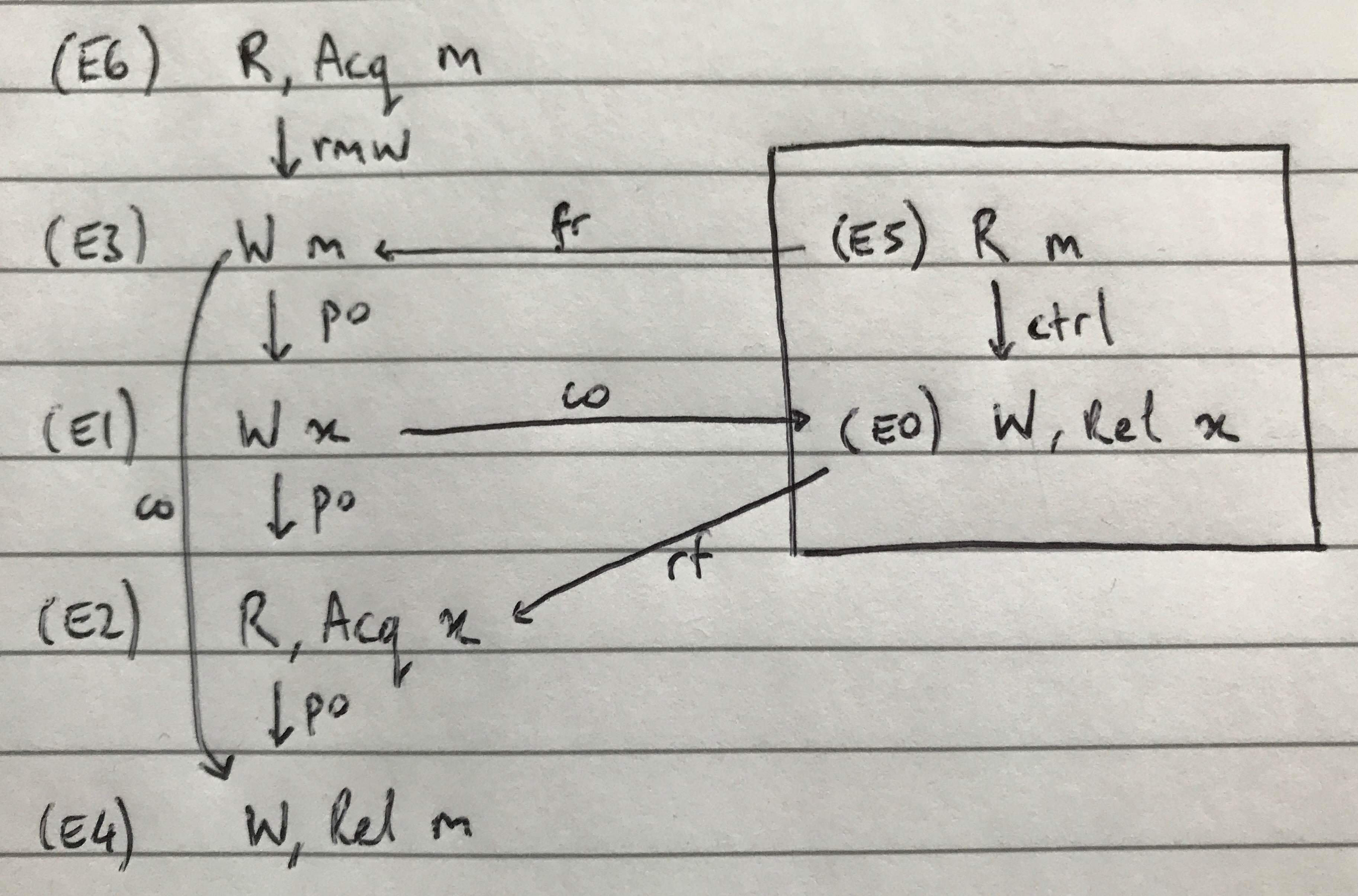
The last thing of note is the atom relation between E6 and E3, which means they form a successful read-modify-write. Putting this all together we can redraw the concrete execution as follows. The execution is consistent with respect to our transactional ARMv8 memory model.
- E6: The left thread reads the lock variable as free
- E1: The left thread writes the shared variable
xto 1 - E5; E0: The right thread starts a transaction, sees the lock is free, updates
xand commits its transaction - E3: The left thread updates
mto 1 (taken). This is a successful read-modify-write paired with the read of E6. - E2; E4: Finally, the left thread reads
x(from the write of E0) and releases the lock variable
Mapping
Finally, we check the mapping \pi between the abstract and concrete executions. This is a mapping between the 7 events of the abstract execution (labelled E0..E6) and those of the concrete execution (also labelled E0..E6). Switch back to the abstract execution and roll over the gp_map relation.
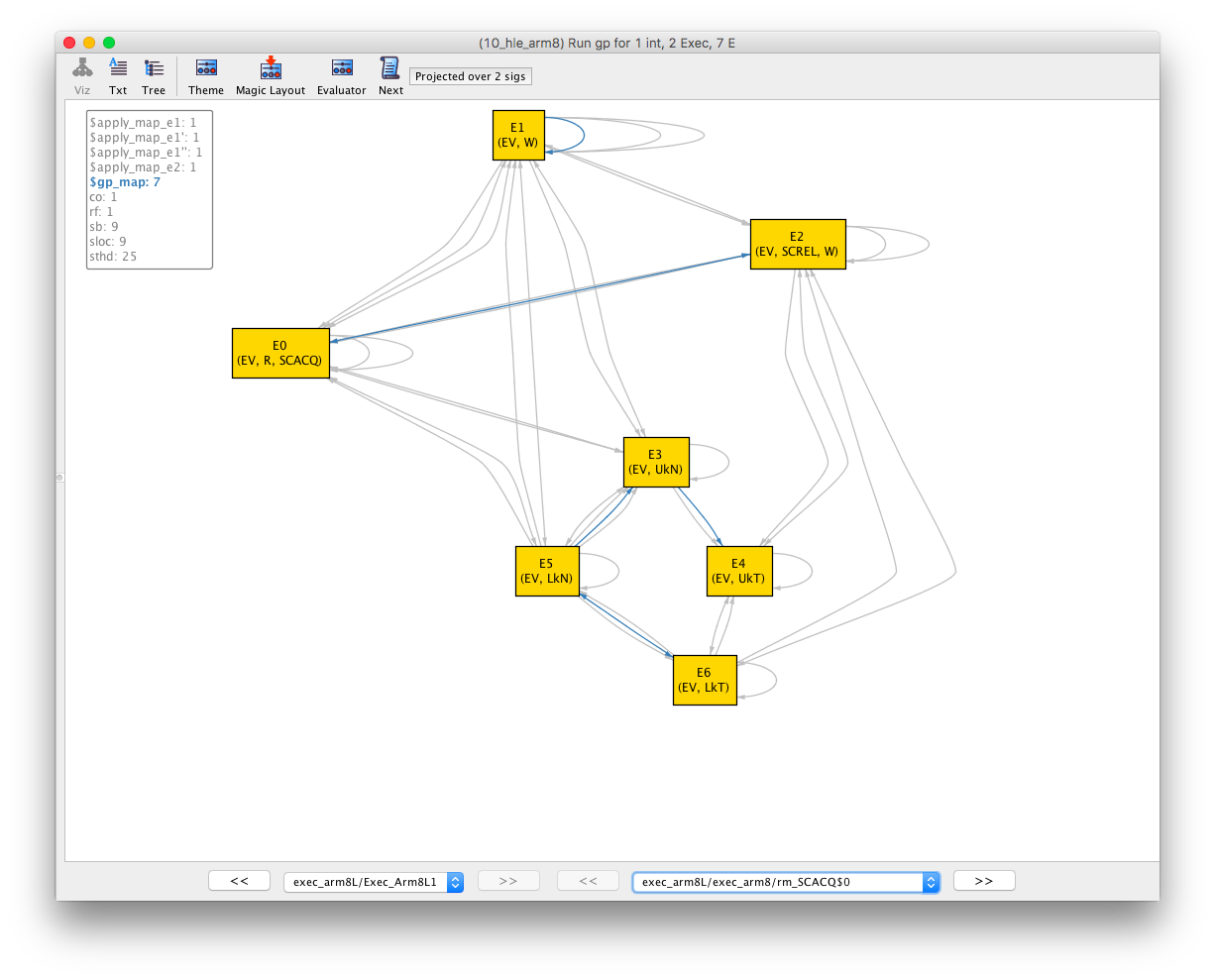
We can read off the following mapping:
- E0 maps-to E2
- E1 maps-to E1
- E2 maps-to E0
- E3 maps-to E4
- E4 maps-to No event
- E5 maps-to E3 and E6
- E6 maps-to E5
Or, even better, draw the mapping:
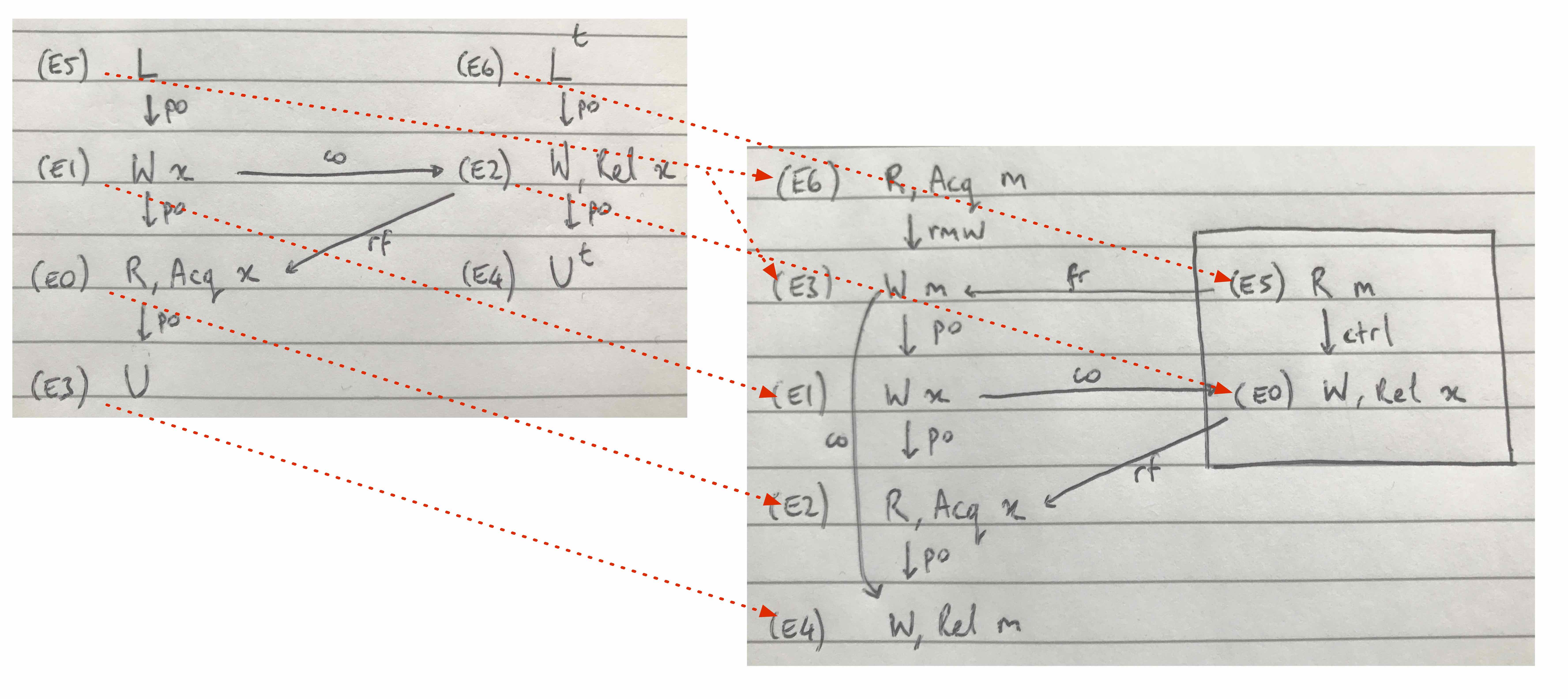
Notice that E5, the abstract L (lock) event, maps to the concrete events E3 and E6, the paired read-modify-write events; and E4, the abstract U^t (elided tx unlock) event, maps to no events.